
When working with PyTorch and CUDA, you might encounter errors like “Cannot pin ‘torch.Cuda.LongTensor’: only dense CPU Tensors can be pinned.” This can be unclear, especially if you’re new to deep learning.
Getting the error “Cannot pin ‘torch.Cuda.LongTensor’: only dense CPU Tensors can be pinned” in PyTorch? This happens because only CPU Tensors support pinning. Fix it by converting the Tensor to CPU using .cpu() before pinning for faster data transfer.
In this article, we’ll explain why this happens, how to fix it, and alternative ways to optimize your model’s performance. Whether you’re troubleshooting errors or looking to improve speed, this guide will help you better understand PyTorch pinning.
Understanding ‘Cannot Pin ‘torch.cuda.longtensor’ Only Dense CPU Tensors Can Be Pinned’
When working with PyTorch, you might see this error when pining a torch.cuda.longtensor. This happens because only dense CPU tensors, not GPU tensors, can be pinned. Pinning helps speed up data transfers between CPU and GPU but only works with specific tensor types.
Since torch.cuda.longtensor is a GPU tensor, PyTorch does not allow it to be pinned. To fix this, move the tensor to the CPU before pinning it.
Understanding this error helps you optimize your deep learning models and prevent performance issues when transferring data between CPU and GPU.
1. What is Pinned Memory?
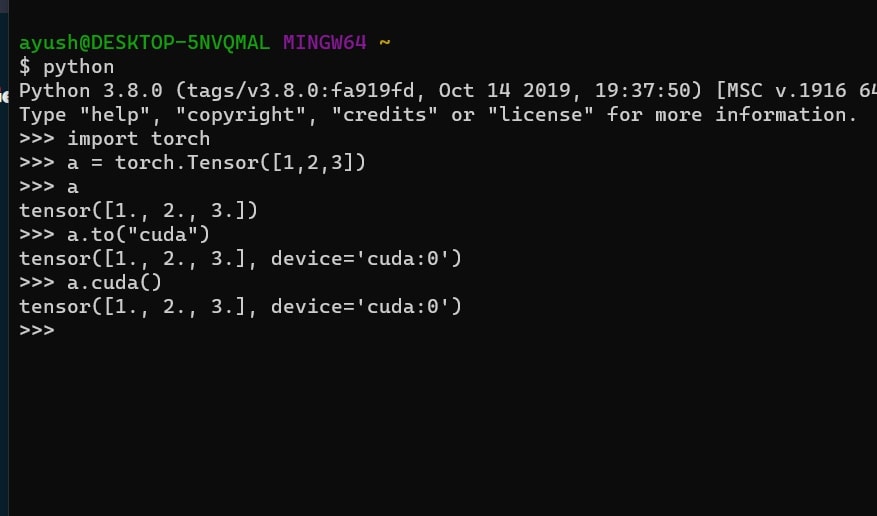
Pinned memory is a special type in PyTorch that transfers data between CPU and GPU faster. Normally, moving data between these devices can slow down performance. However, pinching a tensor stays locked in RAM, allowing the GPU to access it more quickly.
This is useful in deep learning when working with large datasets. You can pin a tensor using a torch.pin_memory(), but only dense CPU tensors can be pinned if you try to pin a GPU tensor, like torch.cuda.longtensor, you will get an error because pinned memory does not support GPU tensors.
A. Restrictions on Pinning long Tensors on the GPU
There are a few crucial reasons why you cannot pin torch.cuda.longtensor in PyTorch. First, pinning is only allowed for CPU tensors, and extended tensors on the GPU are not designed to work with pinned memory.
Second, only dense tensors can be pinned, meaning the data must be stored in a continuous memory block.
However, torch.cuda.longtensor is often sparse, meaning it has gaps in memory, making pinning impossible.
Finally, GPU memory works differently from CPU memory, so pining a GPU tensor does not improve performance. Instead, it’s better to convert the tensor to CPU before pinning.
B. Handling the Error
If you see the error “Cannot Pin ‘torch.cuda.longtensor’ Only Dense CPU Tensors Can Be Pinned,” don’t worry! The easiest way to fix it is by converting your GPU tensor into a CPU tensor before pinning.
You can do this using .cpu() and, if needed, convert it into a dense tensor using .to_dense(). If pinning is unnecessary, you can perform operations directly on the GPU to avoid unnecessary data transfers.
Another option is using torch.cuda.FloatTensor is more compatible with pinned memory. By following these solutions, you can improve the speed and efficiency of your PyTorch model.
2. Next Steps
Now that you understand why torch.cuda.longtensor cannot be pinned; optimizing your workflow is next. Always convert GPU tensors to CPU before pinning. If needed, use alternative tensor types like torch.cuda.FloatTensor.
Also, explore efficient memory management techniques to speed up data transfers. Keep learning and experimenting to improve your PyTorch performance!
Also Read: Soft Lockup CPU Stuck – Step By Step Guide In 2025!
What Are Tensors in PyTorch?
Tensors in PyTorch are like advanced versions of arrays or matrices. They store numbers in multiple dimensions, making them useful for machine learning and deep learning.
They are flexible data containers that can hold anything from simple numbers to complex datasets. Tensors allow efficient mathematical operations, especially when working with GPUs.
Unlike regular Python lists, they are optimized for speed and performance. If you’ve used NumPy arrays before, Tensors work similarly but with extra features.
1. Types of Tensors
PyTorch has different types of tensors, but the main two are dense and spare tensors.
- Dense Tensors store all values, including zeros, in a continuous memory block. These are the most commonly used Tensors.
- Sparse Tensors only store non-zero values, making them more memory-efficient when working with large datasets containing many zeros.
Other types include Float, Long, and Boolean Tensors, each designed for specific data types and operations.
Role of Dense CPU Tensors in Pinning
Dense CPU Tensors are the only ones that can be “pinned” in PyTorch. Pinning means locking the Tensor in memory so data can move faster between the CPU and GPU.
Dense Tensors work because they store data in a continuous block of memory, making them easy to access quickly.
Sparse or GPU Tensors don’t have this structure, so they can’t be pinned. Pinning helps speed up deep learning training by making data transfer much more efficient.
What Are CUDA Tensors?
CUDA Tensors are special PyTorch Tensors that live in the GPU instead of the CPU. They are designed to use GPU processing power, making deep learning models run much faster.
Unlike regular Tensors, CUDA Tensors can’t be pinned because they are already stored in GPU memory. You first move your data to the GPU using .to(‘cuda’) to use them efficiently. This allows you to perform heavy calculations without slowing down your system.
Why Are LongTensors Non-Pinnable?
LongTensors in PyTorch store integer values, but they can’t be pinned because of how they are stored in memory. Pinning works best with floating-point Tensors, commonly used in deep learning.
Since LongTensors often store categorical or index values, they don’t need fast transfers like floating-point data.
You’ll get an error if you try to pin a CUDA LongTensor. To fix this, convert it to a float Tensor before pinning it or avoid it altogether.
Common Use Cases for Pinned Tensors
- Faster Data Transfer – Pinned Tensors speed up data movement between the CPU and GPU.
- Efficient Data Loading – Used in PyTorch’s DataLoader to improve training performance.
- Better GPU Utilization – Reduces waiting time when transferring data during training.
- Handling Large Datasets – Useful for deep learning models working with massive data.
- Optimizing Batch Processing – Helps process multiple data samples quickly.
- Reducing Latency – Improves responsiveness in real-time AI applications.
Troubleshooting Similar Issues
If you’re facing errors related to pinning Tensors in PyTorch, here are some common problems and their solutions.
1. Check If the Tensor Is on the CPU
- PyTorch only allows pinning for CPU Tensors.
- Use .device to check the Tensor’s location:
Print(tensor.device) # Should output “CPU”
- Move it to the CPU using .to(‘cpu’).
2. Ensure the Tensor Is Dense
- Sparse Tensors cannot be pinned.
- Convert a Sparse Tensor to Dense using:
Dense_tensor = sparse_tensor.to_dense()
3. Verify the Tensor Data Type
- LongTensors and some other data types cannot be pinned.
- Convert it to FloatTensor before pinning:
Tensor = tensor.float()
4. Check If the Tensor Is Contiguous
- Some Tensors may not be stored in a continuous memory block.
- Make it contiguous using:
Tensor = tensor.contiguous()
5. Debug with Smaller Tensors
- Test pinning with a small sample Tensor first.
- If it works, gradually scale up to find the issue.
Must Read: Is 40C Good For CPU – A Comprehensive Guide In 2025!
Best Practices for Memory Management in PyTorch
To optimize data transfer and prevent memory-related errors, adhere to the following best practices:
- Pin Memory Strategically: Apply pin_memory to CPU tensors before transferring them to the GPU. This practice ensures efficient data transfer and minimizes latency.
- Leverage Asynchronous Transfers: Use asynchronous data transfers by setting non_blocking=True when moving pinned CPU tensors to the GPU. This approach allows computations to overlap with data transfers, enhancing performance.
Example:
(import torch
# Create a CPU tensor and pin its memory
cpu_tensor = torch.randn(1024, 1024).pin_memory()
# Asynchronously transfer the tensor to the GPU
gpu_tensor = cpu_tensor.cuda(non_blocking=True))
In this example, the pinned CPU tensor is transferred to the GPU asynchronously, enabling potential overlap between data transfer and computation.
- Optimize DataLoader Usage: Configure the DataLoader‘s pin_memory parameter based on the dataset’s location. Set pin_memory=True for CPU datasets to enable pinned memory, and pin_memory=False for GPU datasets to avoid unnecessary pinning attempts.
Dataloader Pin Memory
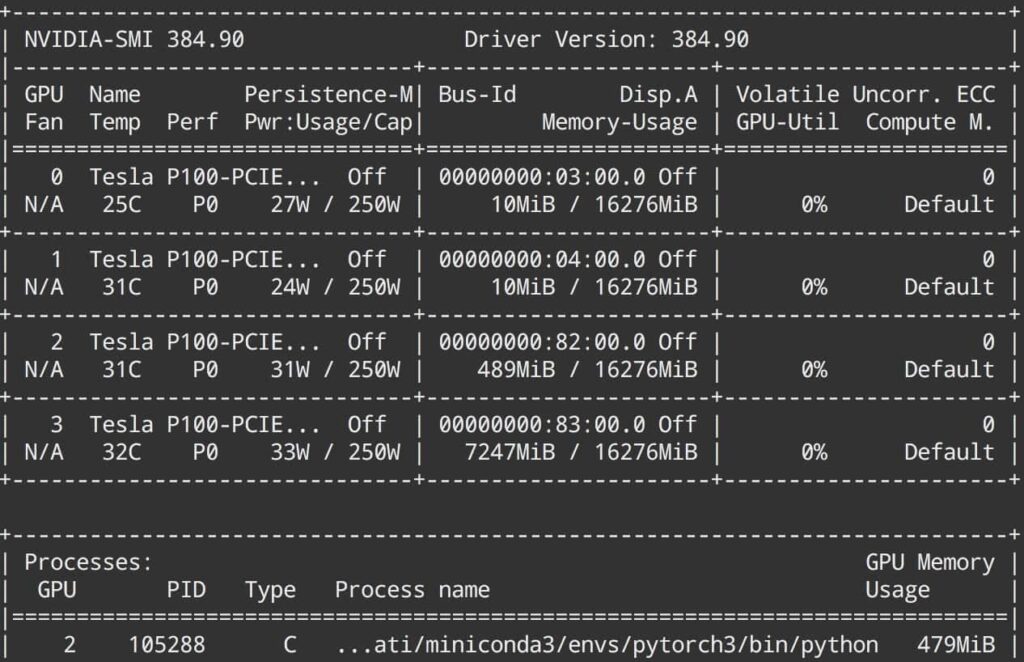
The pin_memory=True option in PyTorch’s DataLoader speeds up data transfer from CPU to GPU. Data is first loaded into pinned memory when enabled, making transfers faster.
This is especially useful for deep learning models. If your training is slow, try turning this on. However, it only works for CPU Tensors, so ensure your data is compatible.
Pytorch Pin Memory Slow
If enabling pin_memory=True slows down your model instead of speeding it up, there may be an issue. Too many pinned Tensors can overload memory, causing slowdowns.
Another reason could be using an old CPU or not having enough RAM. Try reducing batch size or disabling pinning to see if performance improves. Also, check for other background processes using memory.
Runtimeerror: Caught Runtimeerror In Pin Memory Thread For Device 0
This error happens when something goes wrong with the pin memory thread. It might be due to low system memory, incorrect data format, or a bug in PyTorch.
Restarting the training script can sometimes fix it. If the error continues, try running without pin_memory=True or check if your DataLoader works correctly. Updating PyTorch might also help.
Runtimeerror: Pin Memory Thread Exited Unexpectedly
This error means that PyTorch’s pin memory thread stopped working suddenly. Memory issues, system crashes, or PyTorch bugs can cause it.
To fix it, reduce the batch size, turn off pin_memory, or restart your system. If you’re using multiple workers, try lowering the num_workers value. Keeping PyTorch updated can also help prevent this issue.
Using Pin_memory=False As Wsl Is Detected This May Slow Down The Performance
If you’re using Windows Subsystem for Linux (WSL), PyTorch may turn off pin memory automatically because WSL doesn’t handle pinned memory well.
This can make training slower. To speed it up, consider using a native Linux system or switching to WSL 2 with GPU support. You can also test training performance with and without pin_memory=True.
FAQs
1. What is the difference between torch Tensor and torch CUDA Tensor?
A torch. The tensor is stored in CPU memory, while a torch.cuda. The tensor is stored in GPU memory for faster computations using CUDA.
2. What is pinned memory in PyTorch?
Pinned memory locks CPU memory, speeding data transfer between CPU and GPU and improving deep learning model training speed in PyTorch.
3. What is the difference between CPU and GPU Tensor?
CPU Tensors run on the processor, while GPU Tensors use CUDA for faster parallel computations, making them better for deep learning tasks.
4. What is the default Dtype of torch Tensor?
The default data type of a torch.Tensor in PyTorch is torch.float32, which balances accuracy and memory usage well.
5. Is Torch faster than TensorFlow?
PyTorch is often faster for dynamic computations, while TensorFlow can be better optimized for large-scale production workloads and deployment.
6. What is the difference between CUDA Cores and Tensor Cores?
CUDA Cores handle general GPU tasks, while Tensor Cores accelerate deep learning operations like matrix multiplications for better AI performance.
7. Does PyTorch support Tensor Cores?
Yes, PyTorch supports Tensor Cores, improving deep learning performance by automatically using mixed precision for faster computations on compatible GPUs.
8. What is the difference between detach and CPU in PyTorch?
.detach() removes a Tensor from computation graphs, while .cpu() moves a Tensor from GPU to CPU memory.
9. Can I pin other types of GPU Tensors to CPU memory?
No, only CPU Tensors can be pinned. GPU Tensors must first be moved to the CPU before pinning.
10. Are there any alternatives to pinning ‘torch.cuda.LongTensor’?
Yes, you can convert it to a torch.FloatTensor or use efficient data transfer techniques like asynchronous memory copy.
Conclusion
Understanding the “Cannot pin ‘torch.Cuda.LongTensor’: only dense CPU Tensors can be pinned” error is crucial for optimizing PyTorch performance. Since only dense CPU Tensors can be pinned, always convert CUDA Tensors to CPU using .cpu() before pinning. This ensures faster data transfers and prevents unnecessary errors in deep learning workflows.



